A Winning Playbook for A D Tests on Meta and Google
If you've ever felt like you're just throwing money at ads and hoping something sticks, you're not alone. We’ve all been there, watching budgets drain with inconsistent, unpredictable results. The good news is there's a way to stop the guesswork. A disciplined approach to a d tests is the single most effective way to build a winning ad strategy on platforms like Meta and Google.
This playbook is built on years of in-the-trenches experience, designed to help you run ad tests that actually lead to growth.
Stop Guessing and Start Winning with Ad Tests

The best advertisers don't just get lucky; they build a culture of testing. Every campaign, every ad, and every creative is treated as an opportunity to learn something new. The goal isn't to find one magical "perfect ad"—it's to create a system that makes your entire marketing operation smarter with every dollar you spend.
Without a structured testing process, you’re basically gambling. Sure, a creative might go viral, but you won't have a clue why it worked. That means you have no idea how to do it again. A solid testing framework changes everything.
Build a Foundation for Growth
When you commit to running organized a d tests, you start building a powerful feedback loop that pays dividends over time. You’re not just running ads; you’re building an engine for growth.
Here’s what that really looks like:
Stop Wasting Money: You learn to quickly identify and kill underperforming ads, funneling your budget toward what’s been statistically proven to work.
Build a Knowledge Bank: You discover precisely which headlines, images, audiences, and offers resonate. This isn't just data—it's a library of insights you can draw on for every future campaign.
Create Predictable Performance: Instead of chasing one-off wins, you build a foundation for consistent results that can weather the inevitable algorithm changes and market volatility.
The most critical skill for sustainable performance marketing isn't just making ads—it's creating a system to improve them. Structured testing is that system. It turns your ad spend from a daily expense into an intelligent, long-term investment.
Ultimately, this process gives you a clear path forward when performance dips. Instead of panicking, you'll have a backlog of test ideas and a proven framework for finding your next winner. It’s the difference between reacting to the market and leading it. Now, let’s get into the framework that makes it happen.
Build a Smarter Hypothesis for Every Ad Test

A truly great ad test never starts in Ads Manager. It begins with a sharp, testable hypothesis. If you want to get real, actionable insights instead of just random noise, you have to move beyond vague advice like "test your creative."
The most powerful hypotheses come from putting on your detective hat and digging into your performance data. Look for the patterns. Is a low click-through rate (CTR) plaguing a specific audience? That’s a strong signal your headline or image isn't landing. Or maybe your cost per acquisition (CPA) is fantastic, but the leads are junk. That points to a disconnect between what your ad promises and what your landing page delivers.
This kind of groundwork stops you from testing just for the sake of it. Instead, every test becomes a targeted strike aimed at improving a real business metric, not just a shot in the dark.
The Hypothesis Scaffold Framework
To give this process some structure, I use a simple framework for every test I run. I call it the "Hypothesis Scaffold," and it forces you to be crystal clear about what you're doing and why. It’s all about connecting your proposed change directly to a business goal and backing it up with data.
Here’s the formula: By changing [Specific Variable], we predict we can improve [Key Metric] because [Data-Informed Reason].
Using this structure turns a fuzzy idea like "let's test new videos" into a concrete strategy. It’s the difference between a guess and an educated experiment.
A well-formed hypothesis ensures that even a "losing" test is a win. If your hypothesis is disproven, you've still learned something valuable about your audience or offer, saving you from making the same mistake at a larger scale.
Let's say an e-commerce brand is seeing a ton of cart abandonment from ads for a particular product. Their gut, backed by the data, tells them price might be the sticking point.
Vague Idea: "Let's test a discount."
Hypothesis Scaffold: "By changing the offer from 'Shop Now' to 'Get 20% Off Your First Order,' we predict we can improve the purchase conversion rate because our abandonment data suggests a high price sensitivity for first-time buyers."
See the difference? One is a wish, the other is a plan.
Real-World Hypothesis Examples
Applying this framework makes your entire testing roadmap clearer and much easier to defend to your team or clients.
Imagine a SaaS company running ads. They're getting plenty of traffic, but very few people are signing up for a demo, which is their main goal. After digging into their Google Ads account, they notice that visitors from their campaigns only spend an average of 15 seconds on the demo request page.
That’s a huge red flag. It tells them the "Request a Demo" call-to-action (CTA) is probably too much, too soon for a new visitor.
So, they use the scaffold to build a focused hypothesis: "By changing the primary CTA on our landing page from 'Request a Demo' to 'Start a Free Trial,' we predict we can improve our lead-to-MQL (Marketing Qualified Lead) rate because the low time-on-page indicates visitors aren't ready for a sales call, and a lower-friction offer should capture more genuine interest."
This disciplined approach is the foundation of effective a d tests. It’s how you turn your ad account from a potential money pit into a reliable learning engine.
Execute Flawless Ad Tests on Meta and Google
You've got a solid hypothesis. Now comes the hard part: execution. This is where the rubber meets the road, and even the smallest setup mistake can torpedo your entire experiment, wasting budget and delivering data you can't trust. All that strategic work goes right out the window.
Running a clean ad test means getting hands-on with the specific tools inside Meta Ads and Google Ads. While they serve a similar purpose, their testing frameworks are not the same. Knowing which one to use, and how to configure it correctly, is the difference between a clear winner and a confusing mess.
Setting Up Your Test in Meta Ads
For any controlled experiment on Meta, the native A/B Test tool is your non-negotiable starting point. Trying to test by simply running two different ads or ad sets side-by-side is a recipe for disaster due to audience overlap. The A/B Test tool prevents this by creating a true, clean split, ensuring no user sees both versions of your ad.
When you use the tool, you’re forcing the algorithm to isolate your chosen variable—whether it’s a new creative, a different audience, or a specific placement. The system handles the rest, creating separate, non-overlapping groups to deliver your ads to.
A classic—and costly—error I see all the time is leaving placements on "Advantage+ placements" (Automatic) during a test. If your hypothesis is that a new video works best on Reels, you must isolate its delivery to that placement. Letting Meta push it to the Audience Network and Facebook Feed pollutes your results. You won't know if a performance lift came from the creative itself or the fact that it ran in a different spot.
Using Experiments in Google Ads
Over in Google Ads, the equivalent function is called Experiments. This is your go-to for testing everything from bidding strategies and ad copy to landing pages. The setup involves creating a "draft" of your original campaign, applying your change there, and then running it as an experiment against the original.
Let's say you want to prove that a Target CPA bidding strategy can beat your trusty Manual CPC setup. You would create a draft of the campaign, switch the bidding strategy in that draft, and launch it as an experiment with a 50/50 traffic split.
This setup ensures that external factors—like a competitor launching a big sale or a sudden spike in search interest—affect both your control and variant campaigns equally. It’s the only way to get a true apples-to-apples comparison.
To help you decide which tool fits your needs, here's a quick breakdown of how they compare.
Ad Test Type Comparison Meta vs Google
This table offers a quick reference for the primary testing methods on each platform, highlighting their key differences and best use cases.
Test Feature | Meta Ads (A/B Test Tool) | Google Ads (Experiments) |
|---|---|---|
Primary Use Case | Testing single variables like creative, audience, or placement within an ad set. | Testing campaign-level changes like bidding, structure, settings, or landing pages. |
Setup Method | Integrated into the campaign creation flow. Duplicates an ad set or ad and guides you to change one variable. | Create a "draft" of an existing campaign, make changes, then launch the draft as an "experiment." |
Audience Split | Audience-based split. Randomizes users into non-overlapping groups. | Traffic-based split (cookie or search-based). Splits traffic by a set percentage (e.g., 50/50). |
Best For... | Quick, iterative creative or audience tests. Finding winning ad copy or visuals. | More complex, strategic tests with bigger implications (e.g., Smart Bidding vs. Manual). |
While the mechanics differ, both tools are built to achieve the same scientific goal: isolation.
The core principle of a sound ad test is isolation. Whether on Meta or Google, your primary goal during setup is to ensure that only your test variable is different between the control and the variant. Everything else—budget, targeting, and schedule—must be identical.
The most insightful tests also look beyond the ad itself. If your test involves a new landing page, triple-check that your conversion tracking is perfect. It's also critical to avoid making other significant edits to the campaign while the test is running. This can push your ads back into the learning phase and completely skew your results. You can read more about navigating the Facebook Ads learning phase to sidestep these common issues.
Your Pre-Flight Checklist Before Launch
Before you hit that "publish" button, take 60 seconds to run through this checklist. It’s a simple habit that has saved me from countless headaches and wasted budgets.
Variable Isolated? Have I confirmed that I am changing only one thing?
Audience Split Clean? Am I using the platform's official testing tool, not just two separate ad sets?
Budget & Bids Aligned? Are the budget and bid strategy identical for both the control and the variant?
Test Duration Estimated? Have I done a quick calculation to see if the test can reach statistical significance in a reasonable timeframe?
Tracking Verified? Is my pixel or conversion tag firing correctly on all potential conversion actions for all test variants?
Getting these details right builds a foundation of trust in your data. It guarantees that when you're looking at the results, you’re seeing a true signal of performance, not just the noise from a sloppy setup.
How to Interpret Your Ad Test Results
Your test is finished, the numbers are staring back at you, and it’s time to make a call. This is where a lot of marketers stumble. It's tempting to just look at the cost per acquisition (CPA), pick the lowest one, and call it a day. But that's a classic rookie mistake that can cost you dearly.
I've seen it happen a hundred times: an ad with a killer CPA gets scaled, only for the team to discover weeks later that it was driving low-quality leads that never turned into actual revenue. The real art of analysis is looking at the whole story the data is telling, not just the headline.
Look Beyond the Surface-Level Metrics
Think of your main goal—your North Star metric, like Return on Ad Spend (ROAS) or CPA—as the destination. The secondary metrics, like click-through rate (CTR) and conversion rate (CVR), are the turn-by-turn directions that tell you exactly how you got there.
Here are a couple of common scenarios you'll run into:
High CTR, Low CVR: This is a big one. It tells me your ad creative is magnetic—it's grabbing attention and earning the click. But the magic stops there. The landing page isn't delivering on the promise, creating a disconnect that kills the conversion. The problem isn't the ad; it's what happens after the click.
Low CTR, High CVR: This is an interesting one. Your ad might not be flashy, but the people who do click are converting at an incredible rate. This signals that your message is resonating deeply with a very specific, motivated slice of your audience. The ad is acting like a powerful filter.
Understanding this interplay is what separates good media buyers from great ones. It tells you whether to tweak your landing page, sharpen your ad's hook, or double down on a niche but highly effective creative. Of course, none of this matters if your test setup was messy from the start.
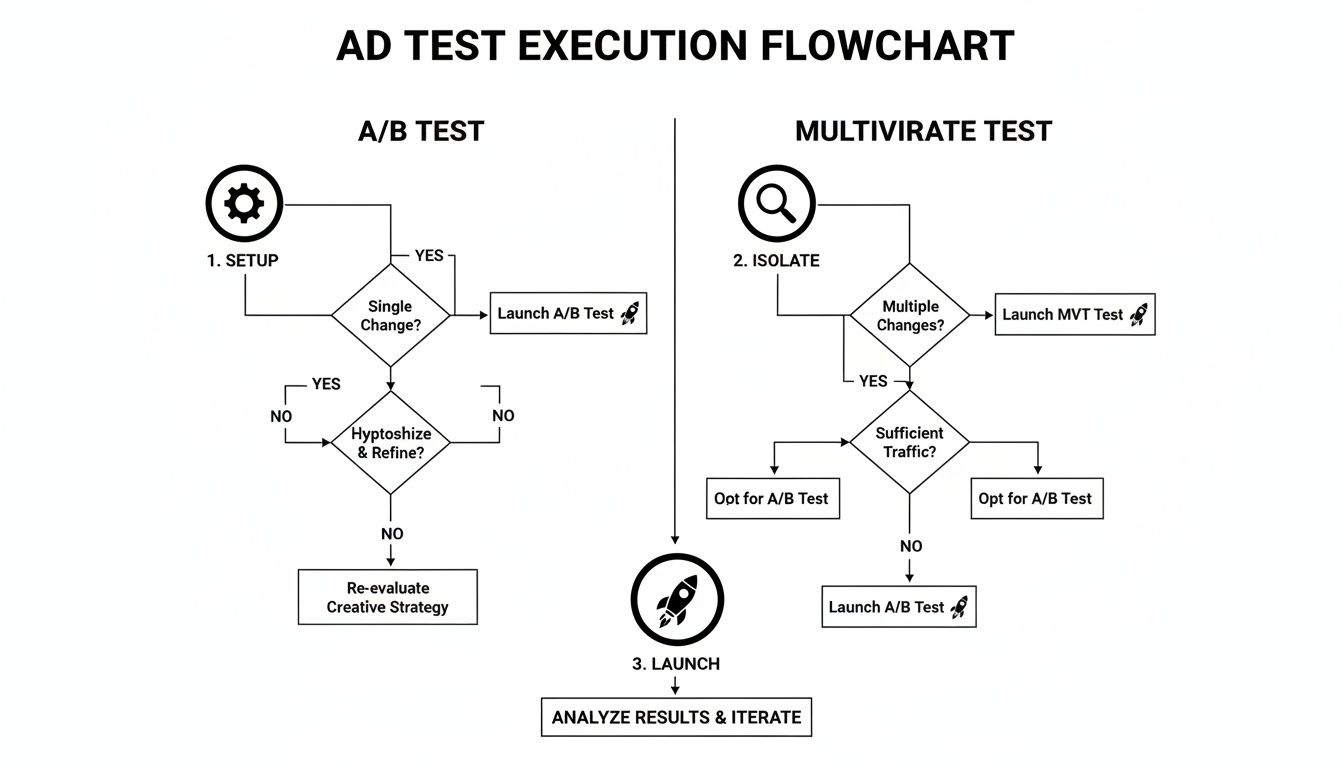
This process is your foundation. Getting the setup, isolation, and launch right ensures the data you’re analyzing is actually trustworthy.
Your Go-Forward Plan: Scale, Iterate, or Kill?
Okay, you've dug into the primary and secondary metrics. Now you have to decide what to do next. To avoid getting stuck in "analysis paralysis," it helps to have a simple playbook.
Don't get fooled by a false positive. Before you declare a winner, always check for statistical significance. You're looking for a 90-95% confidence level. Anything less, and there’s a good chance the result was just random noise. Calling a winner too early is one of the fastest ways to burn through your budget.
Here’s a practical guide for your next move:
You have a clear winner. If one variant smashed the control on your primary metric and the results are statistically significant, it's time to scale. Start by gradually shifting more budget to the winner. Keep a close eye on performance, as you'll want to watch for any signs of creative fatigue.
The results are mixed. What if your new ad has a much higher CTR but a slightly lower ROAS? Don't kill it! This is a huge learning opportunity. The high CTR proves your new hook works. Your next test could be pairing that winning creative with a new offer or a revised landing page to lift the conversion value. Isolate the winning element and test again.
It's a wash. Sometimes, the results are just too close to call, or the confidence level is too low. This usually points to a sample size issue—you didn't let the test run long enough to get a clean read. You can either extend the test or just call it inconclusive and move on to your next hypothesis. Clean data is everything, which is why having your tracking in order is non-negotiable. If you need a refresher, our guide on setting up UTMs for Google Analytics is a great place to start.
You have a clear loser. If a variant bombed across the board, the decision is easy. Kill it. But don't just archive it and forget. Document the learning—for example, "UGC-style creative underperformed studio shots for this cold audience." That insight is gold for your next creative brief.
Scaling Wins and Building a Testing Flywheel
So you’ve run your a d tests, and you have a clear winner. The immediate reaction is to pour money on it and watch the conversions climb. But that's a classic rookie mistake, and it’s one of the fastest ways to kill a winning ad before it ever truly gets going.
Scaling a successful ad is a delicate process. If you abruptly jump the budget by 50% or more, you risk shocking the platform's algorithm. This often throws the ad right back into the learning phase, causing performance to nosedive and erasing all your hard-earned momentum.
The smarter approach is slow and steady. We’ve found the sweet spot is increasing the budget by no more than 20% every 24-48 hours. This gradual ramp-up gives the ad delivery system enough time to explore new pockets of your audience without destabilizing the performance you just validated. If you want to dive deeper into this, we have some discover more about effective scaling techniques that will help protect your campaigns.
From a Single Win to a Testing Flywheel
Here's the thing: a winning ad’s true value isn't just the immediate revenue. It’s the lesson it teaches you. This is how you stop chasing one-off wins and start building a self-sustaining “testing flywheel” that makes your entire account smarter and more efficient.
The flywheel is a simple, powerful cycle. You start with a strong hypothesis based on what you already know, run a clean test to validate it, and then analyze the results to understand why you won or lost. That learning becomes the direct input for your very next hypothesis, creating a loop where growth compounds over time. Your ad account transforms from a money-spending machine into a knowledge-building engine.
Building Your Knowledge Base
To keep this flywheel spinning, you have to meticulously document every test. It doesn't need to be some complex, over-engineered system—a simple spreadsheet or a Notion page works perfectly.
For every single test, you should log the hypothesis, the creative and copy, the core metrics, and most importantly, the key takeaway.
A great takeaway isn't just "Ad B won." It’s "The user-generated video drove a higher CTR than our polished studio ad, which tells us our audience craves authenticity." That single insight is absolute gold for your next creative brief.
This knowledge base becomes your team's single source of truth. It stops you from repeating costly mistakes and ensures you're always building on what you've learned. It should inform everything from future ad creative and messaging to your audience targeting strategies. The goal is to make every dollar spent an investment in making the next dollar work twice as hard.
With global digital ad spend soaring past $780 billion in 2026—and platforms like Meta and Google capturing the lion's share—you can't afford to be inefficient. You can read more about the latest digital advertising trends to see just how competitive it's getting. In this environment, a disciplined cycle of testing and learning is your best defense against wasted spend.
Common Questions from the Ad Testing Trenches
Even with the best-laid plans, you're going to have questions pop up as you get your hands dirty with ad testing. It happens to everyone. Let's walk through some of the most common ones I hear from marketers and get you clear, straightforward answers.
How Long Should My Ad Tests Actually Run?
This is probably the number one question, and the answer isn't a simple number of days. The real goal is to reach statistical significance.
As a general guideline, I recommend running any test for a minimum of 7-14 days. This helps smooth out the natural ups and downs you see in performance from, say, a Tuesday to a Saturday.
But time is only half the equation. You need enough data. Before you even think about launching, plug your numbers into an online sample size calculator. This will tell you roughly how many conversions or clicks you need to get a clear winner. Your test is done when you hit that data threshold with at least 90% confidence—not just because a week went by.
What's the Difference Between an A/B Test and an A/D Test?
You’ll hear these terms thrown around, sometimes to mean the same thing, but they are fundamentally different strategies.
A/B Test: Think of this as a true scientific experiment. You use the platform's native testing tool to test one, and only one, variable between two ads (Ad A vs. Ad B). The tool ensures the audience is split cleanly, giving you results you can trust completely.
A/D Test: This is more of an industry shorthand. It's what happens when you dump several different ads (Ad A, B, C, and D) into one ad set and let the algorithm figure out which one to push. It's less of a controlled test and more of a "creative shootout."
Use A/B tests for big, strategic questions where you need rock-solid proof (like testing a new discount offer). Use A/D tests for rapid-fire creative iteration to quickly find the strongest ad in a batch.
Can I Test More Than One Thing at a Time?
In a proper A/B test? Absolutely not. You must isolate a single variable. For instance, you could test two different headlines, but the image, body copy, and call-to-action must stay exactly the same.
If you change both the headline and the image, you'll have no idea which element actually caused the performance shift. Sure, complex multivariate tests exist, but they demand huge budgets and traffic levels that most of us simply don't have. For 99% of marketers, sticking to single-variable tests is what delivers clear, actionable insights.
What’s a Good Sample Size for My Test?
There’s no magic number here. Your ideal sample size depends entirely on your baseline conversion rate and the "minimum detectable effect" you're looking for—basically, how big of a lift you need to see to care about the result. If you're hoping to detect a tiny improvement, you'll need a massive sample size.
For a practical starting point, many of us aim for at least 100 conversions per variant. But that's just a rough benchmark. The only reliable way to know for sure is to use a free online Sample Size Calculator before you launch. This one step will save you from so much wasted ad spend and inconclusive results.
Stop guessing what's driving performance. SpendOwlAI delivers a daily execution plan with clear, data-backed actions for your Meta and Google ads. Start your free 7-day trial today.